The idea of internal no-code platforms
tl;dr
- Internal no-code platforms with proprietary primitives
- Engineers build and own lower-level primitives
- LLMs orchestrate primitives and use templates as starting points
- Copy/pasteable software components will grow
- Human oversight remains crucial for the foreseeable future
- Enabling “idea guys”™️ to ship products
What are the primitives?
They’re the basic, reusable building blocks that you often use. In software development, they come at different abstractions. On one end you have the data structures, algorithms and protocols. On the other end you have the UI components, APIs, and services. Today we’ll explore the primitive building blocks in software development and have a glimpse into what the future could look like.
Internal no/low-code platform
Imagine a no/low-code platform built specifically for internal use cases, leveraging proprietary primitives. This concept is not entirely new - it’s how many code platforms are built today, and they people seem to enjoyt that. The key difference lies in the integration of LLMs for orchestration.
Here’s how it might work:
-
Foundation
Engineers create lower-level primitives - these could be custom UI components, data models, or business logic modules specific to your organization. -
LLM orchestration
LLMs are then used to orchestrate these primitives, combining them in ways that solve specific business problems or create new features. -
Human guidance
While we can use LLMs to do a lot, humans will still be required. For a while
It enables non-technical team members, like the “idea guy”™️, to build software, experiment with ideas, and launch projects faster. All in a consistent way.
Building the primitives
When it comes to building primitives, humans still need to be in the driver’s seat. LLMs are cool and all, but they’re not quite there yet when it comes to accuracy and reliability. We humans (well some of us) have this knack for creating components that work well together, are maintainable, and can be easily debugged when shit hits the fan (and it will).
On the other hand, it’s probably just a matter of time before we can source this too.
Examples
Let’s look at some concrete examples of how primitives and the Template + LLM approach are evolving in different areas. What can make these approaches successful is that they are:
- Constrained
- Self-owned
- Composable
Content creation
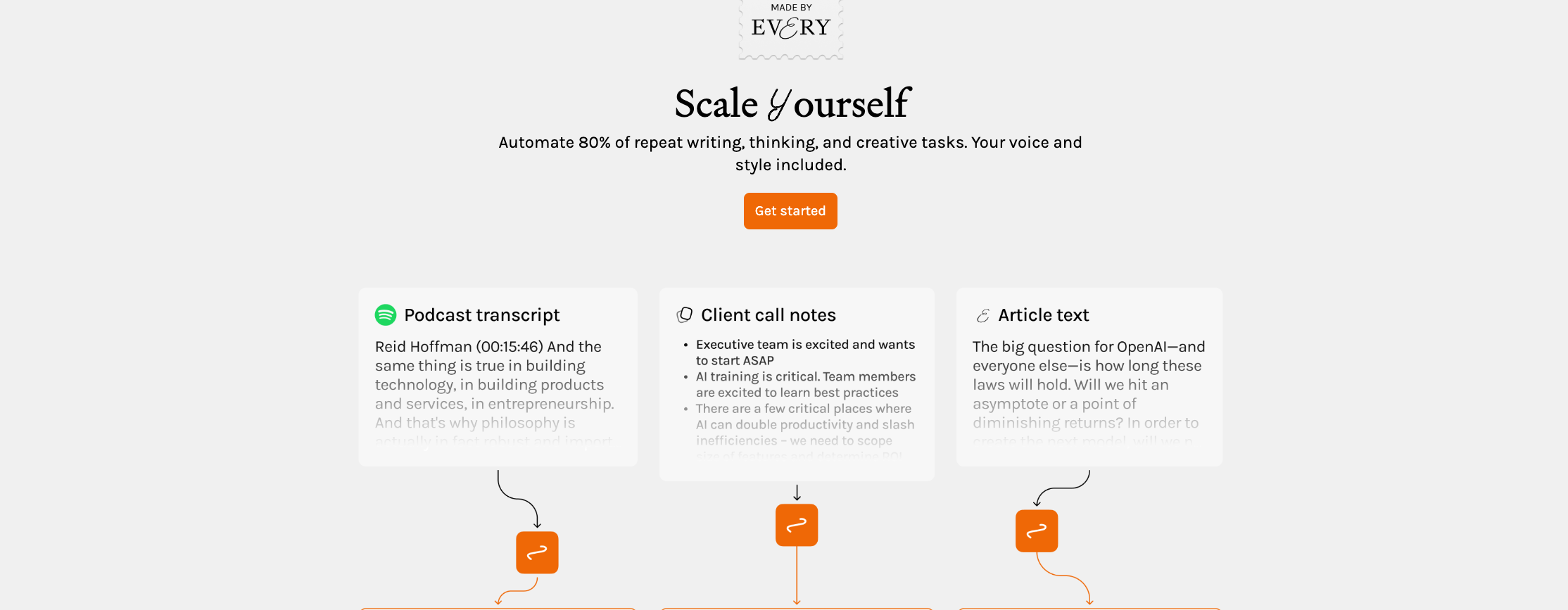
Spiral is an excellent example of how the concept of primitives and LLM orchestration is being applied to content creation. Developed by Every, Spiral aims to “automate 80% of repeat writing, thinking, and creative tasks” while maintaining your unique voice and style.
Here, the primitives are your voice, style, tone and structure. Curious to see how this evolves.
UI Components
The web, with help from frameworks such as React, Vue etc, has adopted the primitives in the form of components making it an a good example of this evolution. Here are some React projects that eventually evolved into the modern UI component landscape and will be fit for LLM orchestration:
It was one of the most influential and widely adopted early CSS-frameworks. It became popular because it’s so easy to use and is easy to adopt to what you need. It sped up development time, ensured cross-browser compatibility, and provided a consistent look and feel across websites
<!-- Stack the columns on mobile by making one full-width and the other half-width -->
<div class="row">
<div class="col-xs-12 col-md-8">.col-xs-12 .col-md-8</div>
<div class="col-xs-6 col-md-4">.col-xs-6 .col-md-4</div>
</div>One of the most popular libraries for React. They “componetized” a lot of UI, making it easy to reuse across your apps. It comes with a comprehensive set of pre-built, customizable components that initially only implement Google’s Material Design.
Similar to Material UI, but with the big difference of the components being copy/pasteable. This became incredible popular because it’s so easy to use and is easy to adopt to what you need. It’s built on top of Tailwind and Radix, two popular tools of our time.
Since it lives in your code base, it’s easy to customize to your own needs. What makes it even more insteresting is the fact that it live in your code base, making it indexeable together with the rest of your code. This provides good context for LLMs and especially tools like Cursor.
Here’s how it can be used with orchestration:
Prompt:
I want a theme that is cartoony, but still has a lot of depth.
Output:
:root {
--background: 0 0% 100%;
--foreground: 222.2 47.4% 11.2%;
--border-width: 2px;
--border-radius: 12px;
--border-color: hsl(var(--foreground) / <alpha-value>);
}export function Button() {
return <button className="bg-background radius">Click me</button>;
}Having tried this for a while, I know it’s a good recipe for generating UI with prompting. And I’m not the only one who think so. The folks at v0 seems to be working exaclty on this, as well as many others.
Event Driven Architecture
I think it’s possible to draw a parallel between the IaC and UI components. Let’s take AWS as an example:
- SQS + SNS in AWS CloudFormation
CloudFormation templates, while powerful, can be verbose and complex. They use JSON or YAML to declaratively define AWS infrastructure. Here’s an example that sets up an SQS queue with an SNS topic and subscription:
{
"AWSTemplateFormatVersion": "2010-09-09",
"Description": "A complex SQS queue with SNS topic, DLQ, and Lambda integration",
"Parameters": {
"Environment": {
"Type": "String",
"AllowedValues": ["dev", "staging", "prod"],
"Default": "dev"
}
},
"Mappings": {
"EnvironmentConfig": {
"dev": {
"QueueRetentionPeriod": 345600,
"TopicDisplayName": "DevTopic"
},
"staging": {
"QueueRetentionPeriod": 604800,
"TopicDisplayName": "StagingTopic"
},
"prod": {
"QueueRetentionPeriod": 1209600,
"TopicDisplayName": "ProdTopic"
}
}
},
"Resources": {
"MyQueue": {
"Type": "AWS::SQS::Queue",
"Properties": {
"QueueName": { "Fn::Sub": "${AWS::StackName}-${Environment}-Queue" },
"VisibilityTimeout": 60,
"MessageRetentionPeriod": {
"Fn::FindInMap": [
"EnvironmentConfig",
{ "Ref": "Environment" },
"QueueRetentionPeriod"
]
},
"RedrivePolicy": {
"deadLetterTargetArn": { "Fn::GetAtt": ["MyDeadLetterQueue", "Arn"] },
"maxReceiveCount": 5
}
}
},
"MyDeadLetterQueue": {
"Type": "AWS::SQS::Queue",
"Properties": {
"QueueName": { "Fn::Sub": "${AWS::StackName}-${Environment}-DLQ" },
"MessageRetentionPeriod": 1209600
}
},
"MyTopic": {
"Type": "AWS::SNS::Topic",
"Properties": {
"TopicName": { "Fn::Sub": "${AWS::StackName}-${Environment}-Topic" },
"DisplayName": {
"Fn::FindInMap": [
"EnvironmentConfig",
{ "Ref": "Environment" },
"TopicDisplayName"
]
},
"KmsMasterKeyId": { "Ref": "MyTopicKey" }
}
},
"MyTopicKey": {
"Type": "AWS::KMS::Key",
"Properties": {
"Description": "KMS key for SNS topic encryption",
"KeyPolicy": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Enable IAM User Permissions",
"Effect": "Allow",
"Principal": {
"AWS": { "Fn::Sub": "arn:aws:iam::${AWS::AccountId}:root" }
},
"Action": "kms:*",
"Resource": "*"
}
]
}
}
},
"MySubscription": {
"Type": "AWS::SNS::Subscription",
"Properties": {
"TopicArn": { "Ref": "MyTopic" },
"Protocol": "sqs",
"Endpoint": { "Fn::GetAtt": ["MyQueue", "Arn"] },
"FilterPolicy": {
"event_type": ["create", "update", "delete"]
}
}
},
"MyLambdaFunction": {
"Type": "AWS::Lambda::Function",
"Properties": {
"FunctionName": {
"Fn::Sub": "${AWS::StackName}-${Environment}-Processor"
},
"Handler": "index.handler",
"Role": { "Fn::GetAtt": ["MyLambdaExecutionRole", "Arn"] },
"Code": {
"ZipFile": {
"Fn::Join": [
"\n",
[
"exports.handler = async (event) => {",
" console.log('Received event:', JSON.stringify(event, null, 2));",
" // Process the event",
" return { statusCode: 200, body: 'Event processed successfully' };",
"};"
]
]
}
},
"Runtime": "nodejs20",
"Timeout": 30,
"Environment": {
"Variables": {
"QUEUE_URL": { "Ref": "MyQueue" },
"TOPIC_ARN": { "Ref": "MyTopic" }
}
}
}
},
"MyLambdaExecutionRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": ["lambda.amazonaws.com"]
},
"Action": ["sts:AssumeRole"]
}
]
},
"ManagedPolicyArns": [
"arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
],
"Policies": [
{
"PolicyName": "LambdaSQSPolicy",
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sqs:ReceiveMessage",
"sqs:DeleteMessage",
"sqs:GetQueueAttributes"
],
"Resource": { "Fn::GetAtt": ["MyQueue", "Arn"] }
}
]
}
}
]
}
},
"MyEventSourceMapping": {
"Type": "AWS::Lambda::EventSourceMapping",
"Properties": {
"BatchSize": 10,
"Enabled": true,
"EventSourceArn": { "Fn::GetAtt": ["MyQueue", "Arn"] },
"FunctionName": { "Ref": "MyLambdaFunction" }
}
}
},
"Outputs": {
"QueueURL": {
"Description": "URL of the SQS Queue",
"Value": { "Ref": "MyQueue" }
},
"TopicARN": {
"Description": "ARN of the SNS Topic",
"Value": { "Ref": "MyTopic" }
},
"LambdaFunctionARN": {
"Description": "ARN of the Lambda Function",
"Value": { "Fn::GetAtt": ["MyLambdaFunction", "Arn"] }
}
}
}It get’s the job done, but I’m not really a fan.
A platform for easy backend workflow and function management. I’ve used it extensively and love it so far. It’s just an out of the box solution that actually works.
export const userWorkflow = inngest.createFunction(fnOptions, fnListener,
async ({ event, step }) => {
const similar = await step.run("query-vectordb", async () => {
const embedding = createEmedding(event.data.input);
return await index.query({ vector: embedding, topK: 3 }).matches;
});
const data = await step.run("generate-llm-response", async () =>
await llm.createCompletion({
model: "gpt-3.5-turbo",
prompt: createPromptForSummary(similar),
});
);
await step.run("save-to-db", async () => {
await db.summaries.create({ requestID: event.data.requestID, data });
});
}
);- Concept: CDK Constructs (Primitives) + LLM
Prompt:
Create a service that
- Takes user input text
- Queries a vector database for similar content
- Generates a response using an LLM
- Stores the result in database
Output:
import { z, dataset, external, pipeline } from "@anyblockers/core";
import { articlesTable } from "../blog";
import { usersTable } from "../user";
const summariesTable = dataset.table.define({
name: "summaries",
schema: z.object({
id: z.string(),
articleId: articlesTable.columns.id,
userId: usersTable.columns.id,
summary: z.string(),
}),
});
const llm = external.openai.define({
model: "gpt-5", // 👀
schema: z.object({
summary: z.string(),
}),
});
// Define the workflow pipeline
export const summarizationWorkflow = pipeline.define({
steps: [
(userInput) =>
articlesTable.query({
vector: createEmbedding(userInput),
topK: 3,
threshold: 0.1,
}),
(similarRecords) =>
llm.generate({
prompt: createPromptForSummary(similarRecords),
schema: z.object({ summary: z.string() }),
}),
(generatedSummary, ctx) => ({
id: generateUniqueId(),
originalRecordId: ctx.steps[0][0].id,
summary: generatedSummary.summary,
}),
],
destination: summariesTable,
});This can of course be generated with any opinionated framework. But I think the important part is the opinionated.
Looking at this EDA example, we can see that it’s doable. It’s worth mentioning that this is an incredibly simple example and the real world examples are much more complex. Building a reliable and scalable event driven systems is hard.
Wrapping up
It took a lot of words to just talk about components and integrations, because that’s really what it comes down to. How to get pieces to play well together. I think the winners will be those who can create services with explcit contracts and boundaries. In any case, we’ll probably wider adoption of the copy/paste paradigm exemplified by shadcn patterns.
And we’ll still require humans in the loop for a while. For now.
This has been a thought experiment, thanks for following along :)