How we systematically analyze user feedback with LLMs
tl;dr
- LLMs can be effectively used to classify user feedback sentiment and extract specific keywords mentioned, even in multilingual contexts.
- Providing contextual examples increases extraction performance when moving towards a set vocabulary in user feedback analysis.
- Letting humans correct system output is very good to help refine the model in an intuitive way
- Building a production-ready AI pipeline goes beyond data & models, involving business goals, product metrics, infrastructure, and ongoing maintenance.
Recently my friends at Qualtive reached out and asked if I could help them build a pipeline to extract sentiment and keywords from their data. So I figured I’d write the process and approach we took.
Qualtive is a tool to collect user feedback from digital products and understand how your product is performing. They have heaps of feedback from users who put in a score, optionally write a complementary text and upload images. Today we’re focusing on the text, and more specifically determining:
- If a feedback is a Complaint, Suggestion or Compliment. We’re calling this Topic
- What areas of the product the user is mentioning. Customer Support, Notifications etc. We’re calling these Subjects
By systematically understanding this, Qualtives customer can over time understand which parts of their product is working well and which one deservers more attention. A product managers dream, one could say. Let’s see how we go about implementing this.
Plan & Design
We’ll be using an off-the-shelf LLM to do the classification and extraction. It’s fast to setup, low(er) maintenance and fairly cheap in relation to the business value is creates.

Goals & Requirements
There are some things we need to take into consideration when designing this solution:
- The production system will be written in Swift (yes, on the server), thus we can’t work with libraries for other reasons that discovery & evaluation
- All feedback will be processed in a background job as they come in.
- Learnings & velocity is more important than cost (for now)
- Subjects will be an ever evolving dataset
- Subjects should be consistent over time to find trends
- Customers should manually be able to adjust subjects
- Customers will probably have overlapping subjects. Most digital products have some kind of sign in, customer support etc in-app.
- Customers will have highly specific terms and vocabulary such as features and domain terms.
- Topic & Subjects will be stored in Postgres
- OpenAI is the vendor we’ll be using (for legal reasons)
With this in mind, we’ll go ahead and create a reference implementation in Python that can later be ported to Swift + Postgres.

Dataset
Before we start proompting, let’s have a look at the dataset we got to work with. Here’s a sample of (anonymized) data.
| Enquiry | User | Feedback | Score |
|---|---|---|---|
| How would you rate your experience with our app? | 1001 | The app is easy to use, but sometimes it’s slow to load. | 75 |
| What difficulties did you encounter while using our service? | 1002 | I couldn’t find the option to change my password. Very frustrating! | 30 |
| What do you think about our latest update? | 1003 | The new feature for tracking shipments is fantastic! Saves me a lot of time. | 95 |
- Enquiry: Question the user is prompted to ask in the product?
- User: User
- Feedback: The free form text user has written
- Score: 0-100. Can be thumbs up/down, 1-5 etc. Also nullable.
We went ahead and labelled a smaller set manually (~100) so it looked like this
| Enquiry | User | Feedback | Score | Topic | Subjects |
|---|---|---|---|---|---|
| How would you rate your experience with our app? | 1001 | The app is easy to use, but sometimes it’s slow to load. | 75 | Complaint | Usability, Performance |
| What difficulties did you encounter while using our service? | 1002 | I couldn’t find the option to change my password. Very frustrating! | 30 | Complaint | Password, Navigation |
| What do you think about our latest update? | 1003 | The new feature for tracking shipments is fantastic! Saves me a lot of time. | 95 | Compliment | Shipping |
Worth noting is that >95% of this data is in nordic languages, making it possible harder for the LLM.
Topic classification
We want the text to be labelled into 3 categories (or “None”). These are the methods we tried:
- Zero-shot prompts
- Including & excluding feedback metadata such as score and enquiry
- Embedding the feedback text and the predetermined topics, then measuring the cosine distance.
We also found that using the term “Question” worked slightly better than Enquiry for the prompts, so that’s what we’ll use.
Methods
Zero Shot
system_prompt = f'''
You're designed to extract the type of feedback the user is providing related to the service they're using ({customer}) from text and score.
The score is between 0-100. If it's a high score, it's more likely a compliment. If it's a low score, it's more likely a complaint.
If the user is requesing a freature or change, it's a suggestion.
Your options are "Complaint", "Suggestion", "Compliment" and "None".
You must only return one option. Fallback to "None" if unsure.
'''
user_prompt = f"""
Question: {question}
Answer: {text}
Score: {score}
Type:"""
def classify_topic(feedback: Feedback, customer: str):
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt.format(customer=customer)},
{"role": "user", "content": user_prompt.format(
question=feedback["Enquiry"],
text=feedback["Text"],
score=feedback["Score"]
)}
],
max_tokens=10
)
return response.choices[0].message.contentEmbeddings
from openai import OpenAI
client = OpenAI()
def get_embedding(text):
response = client.embeddings.create(
input=text,
model="text-embedding-3-small",
)
return response.data[0].embeddingfrom sklearn.metrics.pairwise import cosine_similarity
topics = [
"Complaint",
"Suggestion",
"Compliment",
"None"
]
topics_descriptive = [
"Complaint about service quality or product functionality",
"Suggestion for improvement, new feature, or service enhancement",
"Compliment or positive feedback on user experience",
"None or unclassified feedback requiring further analysis"
]
topic_embeddings = [get_embedding(topic) for topic in topics]
topics_descriptive_embeddings = [get_embedding(topic) for topic in topics_descriptive]
def classify_topic_embedding(feedback: Feedback, topics: list[str], topic_embeddings: list[list[float]]):
# Get the embedding for the feedback text
text_embedding = get_embedding(feedback['Text'])
# Convert the embedding to a 2D numpy array with one row
text_embedding = np.array(text_embedding).reshape(1, -1)
similarities = cosine_similarity(text_embedding, topic_embeddings)[0]
max_index = similarities.argmax()
return topics[max_index]Evaluation
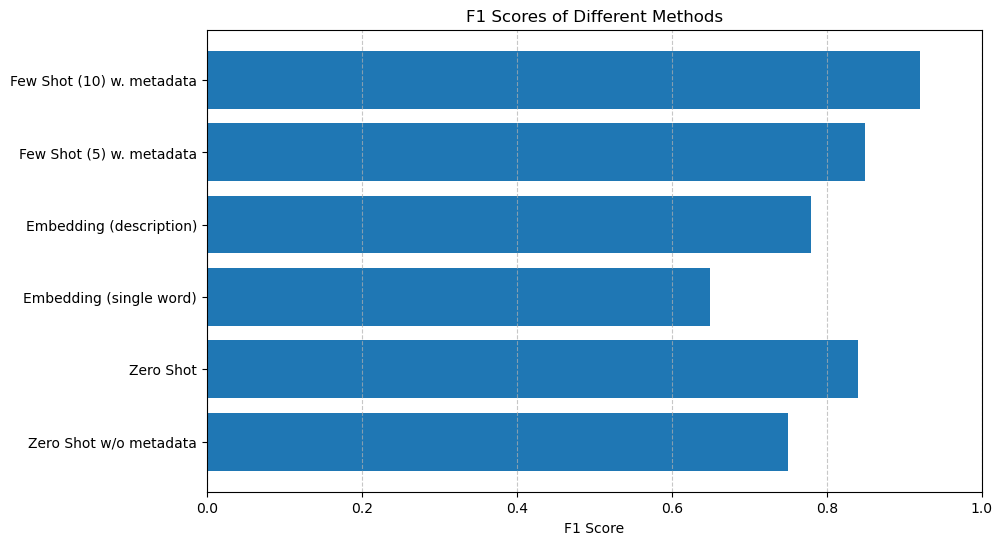
Switching up the models, tuning parameters etc didn’t change much at all. However, providing an even distribution of topics proved much better results than the normal distribution. In the dataset, we can see that 55% of all topics are Compliments, while only 15% are Complaints. Kind of surprising! When we provided an even distribution of topic examples (25% Complaints, 25% Suggestions, 25% Compliments, 25% None) instead of the true distribution (15% Complaints, 55% Compliments etc) we saw a lot of improvement. Using a true distribution of classified topics would probably work better if we provided 25+ examples in the prompt.
I suspect the few-shot is very efficient here due to the multilingual aspect and giving examples in nordic languages helps a lot.
When we check the results, it’s really good. The false negatives is actually not bad, and it mostly get’s it wrong on the ones that humans also could get wrong and where there’s room for ambiguity. Honestly, just labelling this data was a hard since some feedback can be very ambiguous. Just look at these examples:
| Question | Feedback | Score | Topic |
|---|---|---|---|
| How would you rate your experience with our app? | The app is mostly good, but it could be better. | 60 | Suggestion or Compliment? |
| What difficulties did you encounter while using our service? | I had some issues, but they were resolved quickly. | 70 | Complaint? |
| What do you think about our latest update? | It’s okay, I guess. | 50 | None? |
Future improvements
While this is good, we can always do better. Here are some alternatives we’ll look into in the future:
- Use similar feedback by cosine distance and use as examples
- Fine-tuning a smaller language model like
gpt-3.5-turboor an even smaller likebabbage-02 - Fine-tuning a BERT (DistilBERT) model
- Generating more synthetic data to train the models
- More manual labelling
- Collecting implicit feedback by letting humans correct the topic in a UI
- Look into DSPy
We chose not to do that now since the results are good enough™️, and the effort to implement would not provide enough value for now.
Subject extraction
This part is a tad more complicated, but also more interesting!
To recap, the premise here is to extract subjects the user is mentioning in the feedback text. It should over time build up a vocabulary and eventually converge around that. But as the product keeps shipping features, the vocabulary will evolve.
We’ll keep these questions in mind when building out this system:
- What are the common terms found in digital products?
- What are the specialized terms found in this customers digital product?
- When is a subject similar enough to another, i.e a synonym, that we should just use the synonym instead?
- When will new synonyms evolve that won’t be caught by the synonym detection? E.g the scope of a synonym keeps growing because more and more subjects within a threshold is merged.
By answering these questions, we should in theory end up with a system that at ingestion merges similar subjects, but periodically checks the synonyms and either create new subjects or merges the existing ones.
flowchart LR
A["Raw Feedback"] --> B["Subjects extraction"]
B --> C["Find synonym"]
C <--> D[("DB")]
C --> E{"Synonym found? (τ >= 0.75)"}
E -->|Yes| F["Replace with synonym"]
E -->|No| G["Insert subject"]
F --> D
G --> D
D -.-> B
H["Periodically Cluster & Merge"] <--> D
We can also have a look at using the subjects from similar feedback to steer the subject extraction by providiing them as context in the few shot prompt
flowchart LR
A["Raw Feedback"] --> B["Find Similar Feedback with Subjects"]
B -- "Use Subjects as examples" --> C["Subjects Extraction"]
Hopefully these two techniques will let the majority of keywords from the vocab while still allowing for some new ones.
And for the clustering we’ll take inspiration from Valentin Buchner’s article: Enhancing Knowledge Graphs with LLMs: A novel approach to keyword extraction and synonym merging. Highly recommend reading!
Prompt
The prompt we’ll be using to extract.
system_prompt = '''
You're designed to extract subjects from feedback written by users of {customer}.
Only include what the user explicitly mentions in the text.
-----
All subjects MUST BE IN ENGLISH. If there are multiple similar subjects, use only the most relevant one.
The user will also provide a score, so only mention the subject without sentiment.
Provide the subjects in their stem form, in english, separated by commas.
If there are no relevant subjects, don't output anything.'''
user_prompt = 'Feedback: {text}\nSubjects:'
def extract_subjects(feedback: Feedback, examples: List[Feedback], customer: str) -> List[str]:
messages = [
{"role": "system", "content": system_prompt.format(customer)},
]
for example in examples:
messages.extend([
{"role": "user", "content": user_prompt.format(text=example['Text'])},
{"role": "assistant", "content": ", ".join(example['Subjects'])}
])
messages.append({"role": "user", "content": user_prompt.format(text=feedback['Text'])})
response = client.chat.completions.create(
model="gpt-4o",
frequency_penalty=1.5,
temperature=0.0,
messages=messages,
)
text = response.choices[0].message.content.strip()
return [subject.strip() for subject in text.split(',') if subject.strip()]Zero-shot
This won’t end well, but heck. Let’s give it a go.
What find is that we get a lot of subjects in the source language. We explicitly say that we want english, but without examples it seem hard. To my surprise, it’s not too bad for being a extremely generic solution.
| Text | Extracted Subjects |
|---|---|
| The new search feature is amazing, but it’s sometimes slow to load results. I love how it suggests related items though! | search feature, load speed, related item suggestions |
| I can’t figure out how to change my profile picture. The settings menu is confusing and I keep going in circles. | profile picture, settings menu |
| The app crashes every time I try to make a purchase. This is frustrating because I really want to buy that limited edition item before it sells out! | app, crash, purchase, limited edition item |
Few-shot
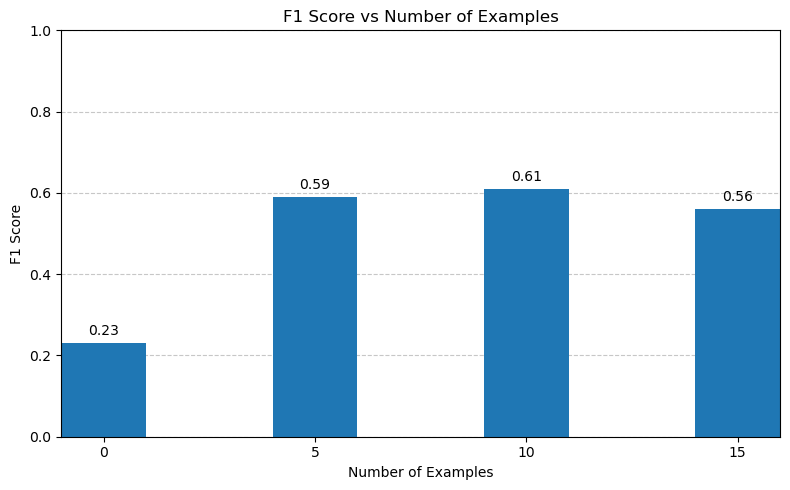
The scores are not impressive. There can be a lot of subjects for, so chances we’re providing relevant ones is not that high. We found that the tone, format etc improved a lot when providing examples. Makes sense.
| Text | Extracted Subjects |
|---|---|
| The new search feature is amazing, but it’s sometimes slow to load results. I love how it suggests related items though! | search, performance, suggested items |
| I can’t figure out how to change my profile picture. The settings menu is confusing and I keep going in circles. | profile picture, settings, navigation |
| The app crashes every time I try to make a purchase. This is frustrating because I really want to buy that limited edition item before it sells out! | app crash, purchase, limited stock |
Similar feedback
Let’s see what happens when we provide examples where the feedback is similar
def find_similar_feedback(feedback: Feedback, feedbacks: List[Feedback], n: int) -> List[Feedback]:
# Get the embedding for the input feedback
input_embedding = np.array(feedback.Embedding)
# Calculate cosine similarity between input and all feedbacks
similarities = cosine_similarity([input_embedding], [f.Embedding for f in feedbacks])[0]
# Get the indices of the n most similar feedbacks
most_similar_indices = np.argsort(similarities)[-n:][::-1]
# Return the n most similar feedbacks
return [feedbacks[i] for i in most_similar_indices]similar_feedback = find_similar_feedback(feedback=feedback, feedbacks=all_customer_feedback, n=n_examples)
subjects = extract_subjects(feedback=feedback, examples=similar_feedback)| Text | Extracted Subjects |
|---|---|
| The new search feature is amazing, but it’s sometimes slow to load results. I love how it suggests related items though! | search, performance, suggested items |
| I can’t figure out how to change my profile picture. The settings menu is confusing and I keep going in circles. | user profile, menu, navigation |
| The app crashes every time I try to make a purchase. This is frustrating because I really want to buy that limited edition item before it sells out! | app, crash, performance, purchase |
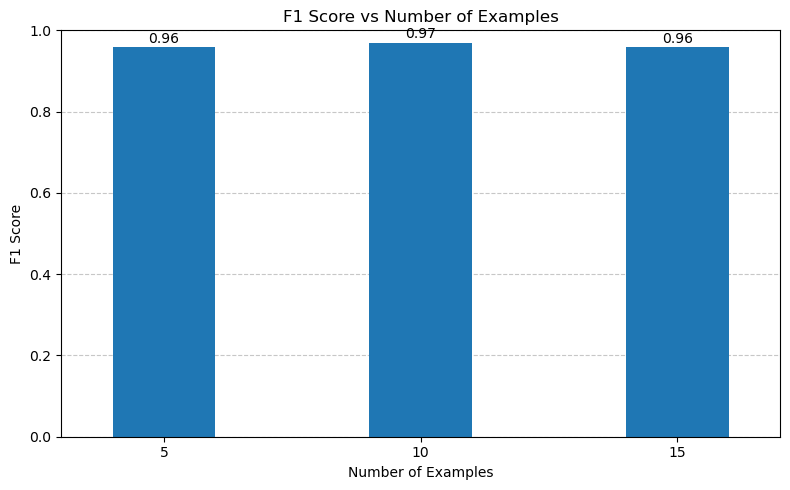
Quite some improvement! This is working very well, but it also requires to good ground truth. Now, one problem remains. We want to reduce the amount of subjects to use synonyms when possible. Our hypothesis is that we can get the subjects to converge around the vocabulary, while still leaving some room for new subjects.
Synonym detection
Here we essentially just want to make the vocabulary more manageable by reducing amount of unique subjects. For that, we’ll use embeddings to determine similarity. We could also implement lexical similarity and do lemmatization, fuzzy seaechgin etc.
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
def find_closest_match(subject: str, vocab: dict[str, np.ndarray], threshold: float) -> str:
subject_embedding = get_embedding(subject)
closest_match: str | None = None
highest_similarity: float = 0.0
for _, row in vocab.iterrows():
existing_subject: str = row['subject']
existing_embedding: np.ndarray = row['embedding']
similarity: float = cosine_similarity(subject_embedding, existing_embedding)
if similarity > threshold and similarity > highest_similarity:
closest_match = existing_subject
highest_similarity = similarity
return closest_match if closest_match else NoneNow, let’s put it to use. Here’s our flow to find closest synonym using embeddings.
vocab = get_customer_vocab(customer)
similar_feedback = find_similar_feedback(
feedback=feedback,
feedbacks=all_customer_feedback,
n=n_examples
)
subjects = extract_subjects(
feedback=feedback,
examples=similar_feedback
)
updated_subjects = []
for subject in subjects:
synonym = find_closest_match(subject, vocab, threshold=0.75)
if synonym is not None:
updated_subjects.append(synonym)
else:
# this is a new subject!
updated_subjects.append(subject)
subject_embedding = get_embedding(subject)
vocab[subject] = subject_embeddingWe loop through the subjects and find the synonym with a threshold of 0.75. We found this threshold to be a good balance between preserving unique subjects while still merging some similar. I do believe we’d get a good performance increase by fine-tuning an embedding model specifically for the type of customers Qualtive will have.
| Text | Extracted Subjects |
|---|---|
| The new search feature is amazing, but it’s sometimes slow to load results. I love how it suggests related items though! | search, performance, recommendations |
| I can’t figure out how to change my profile picture. The settings menu is confusing and I keep going in circles. | profile, menu, navigation |
| The app crashes every time I try to make a purchase. This is frustrating because I really want to buy that limited edition item before it sells out! | app, crash, performance, checkout |
After manually inspecting the subjects, we can tell it’s getting really good. But we had to put in a lot of effort upfront to build out the initial vocabulary. We tried building the vocabulary for each of Qualtives customers by scraping their websites, manually inserting keywords from their apps etc. Then we inserted that in the context of the extractor. After some iterations, it started producing subjects that we could use as examples for our few-shot prompt and thus remove the static keywords. It required a lot of experimentation back and forth, but turned out pretty good.
Clustering
For now this looks good, but in the long term we’ll potentially see some drift in the subjects and their synonyms. To handle this we’ll introduce period clustering of subjects.
def cluster_subjects(
vocab: pd.DataFrame,
n_neighbors: int = 15,
n_components: int = 2,
min_cluster_size: int = 2,
min_samples: int = 1
) -> pd.DataFrame:
embeddings = np.array(vocab['embedding'].tolist())
umap_reducer = umap.UMAP(
n_neighbors=n_neighbors,
n_components=n_components,
metric='cosine'
)
umap_embeddings = umap_reducer.fit_transform(embeddings)
vocab['umap_1'] = umap_embeddings[:, 0]
vocab['umap_2'] = umap_embeddings[:, 1]
clusterer = hdbscan.HDBSCAN(
min_cluster_size=min_cluster_size,
min_samples=min_samples,
metric='euclidean',
cluster_selection_method='eom'
)
cluster_labels = clusterer.fit_predict(umap_embeddings)
vocab['cluster'] = cluster_labels
return vocab
We can experiment with the parameters a bit to find reasonable clusters that’d suitable for merging. Since this post is getting long, we’ll go over the high level post and go into detail in another
- Cluster the subjects
- Merge clusters into a single subjects
- Create mapping/replace subjects with the cluster
- Repeat every n hours, starting with once per day
flowchart TD
A["Start (Every n hours)"] --> B["Cluster the subjects"]
B --> C["Merge clusters into single subjects"]
C --> D["Create mapping/replace subjects with the cluster"]
D --> E["Wait for next scheduled run"]
E --> A
subgraph "Repeat Process"
A
E
end
Next steps
We got it working in our notebook, but the real job lies in shipping this to production. That means:
- Porting the code to Swift & Postgres
- Integrating into existing infrastructure
- Setup monitoring and see how it behaves in production
Measurement & Monitoring
The numbers we’ll be looking at
- Percentage of vocabulary covered
- Rate of new subject introduction
- Consistency of subject extraction over time
- Vocabulary size evolution
These metrics will guide our ongoing refinements and help us understand the system’s effectiveness.
Room for improvement
As we monitor our metrics, we may find areas that need attention. Here are some potential improvements we can explore based on what we observe:
- If we see a low percentage of vocabulary coverage for certain customers, we might implement Named Entity Recognition (NER) for customer-specific vocabulary. This could help us better capture customer-specific terms, features etc.
- Should our synonym detection become too aggressive or too conservative, we could look into an adaptive threshold that adjusts based on vocabulary growth and usage patterns.
- If our vocabulary size grows unwieldy, we might create a mechanism to remove rarely-used subjects. This would keep our subject list manageable without losing valuable terms.
- To address inconsistencies in subject extraction over time, we can introduce a user feedback loop. This would enable Qualtive’s customers to provide input on our extractions, helping us fine-tune the model.
Conclusion
- The LLM approach for topic classification and subject extraction worked well, especially once we tuned it with relevant examples.
- Our multilingual issues mostly went away when we added more diverse and nuanced examples to the prompts. Simple, but effective.
- We had to go back and relabel some of our data. Turns out, the AI was sometimes more accurate than our human labelers. Shit it, shit out 🤷
- Evaluating the system was tricky. It’s hard when even humans can’t always agree on the right answer. We ended up using a mix of metrics and to some extent – vibe checks.
- Being able to correct the output in the UI will be very valuable since it’ll help guide the system and improve accuracy over time
- Moving forward, we’ll need to keep an eye on metrics that (hopefully) track how our system is performing. That’ll tell us where to focus our efforts.
Shout out to Valentin Buchner for bouncing ideas and providing feedback!