Postgres is all you need, even for vectors
tl;dr
- Postgres + pgvector for simplified embedding storage
- Colocate data for easy querying and consistency
- Fast and cost-effective solution
- Knowledge graphs in Postgres
- Hybrid search is tricky but possible

Truly a 🇨🇭 army knife
When working with LLMs, you usually want to store embeddings, a vector space representation of some text value. During the last few years, we’ve seen a lot of new databases pop up, making it easier to generate, store, and query embeddings: Pinecone, Weaviate, Chroma, Qdrant. The list goes on.
But having a separate database where I store a different type of data has always seemed off to me. Do I really need it? Short answer: No. Long answer: continue reading.
I always reach for Postgres when building something AI related (and anything else really). I love it. It’s simple, has a great ecosystem, does its job, can be used as a data warehouse, and has great extensions. The greatness has been outlined by Stephan Schmidt very well here: Just Use Postgres for Everything
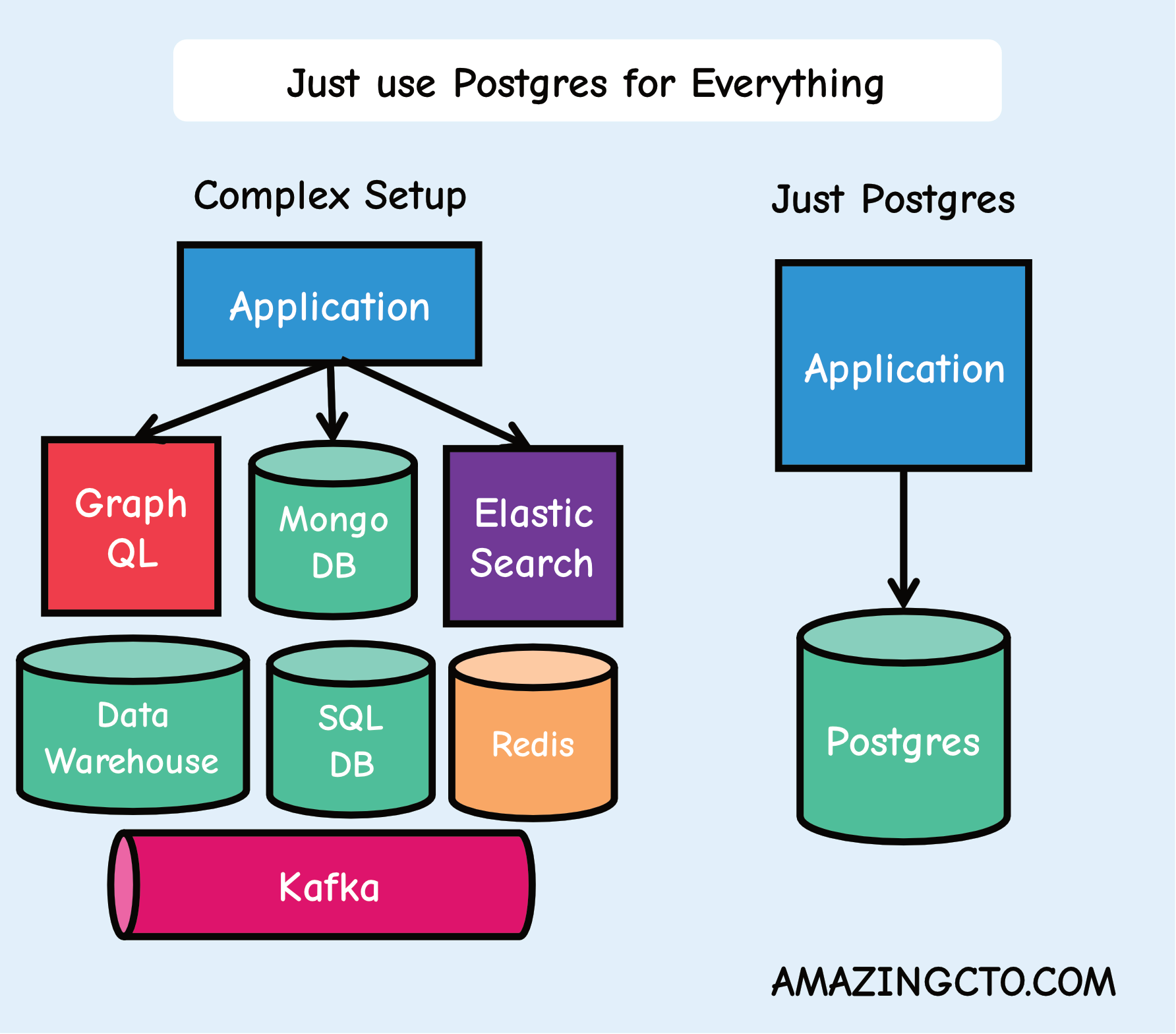
But the greatness doesn’t stop there. Turns out it’s very good for vectors & embeddings with the pgvector extension. This has been like the flag of Switzerland, a big plus.
Vector performance
The notion of Postgres not being performant with vector workloads seems eradicated. In a recent post from TimescaleDB PostgreSQL and Pgvector: Now Faster Than Pinecone, 75% Cheaper, and 100% Open Source, they showed how their new Postgres extension is not only faster but also 75% cheaper than Pinecone.
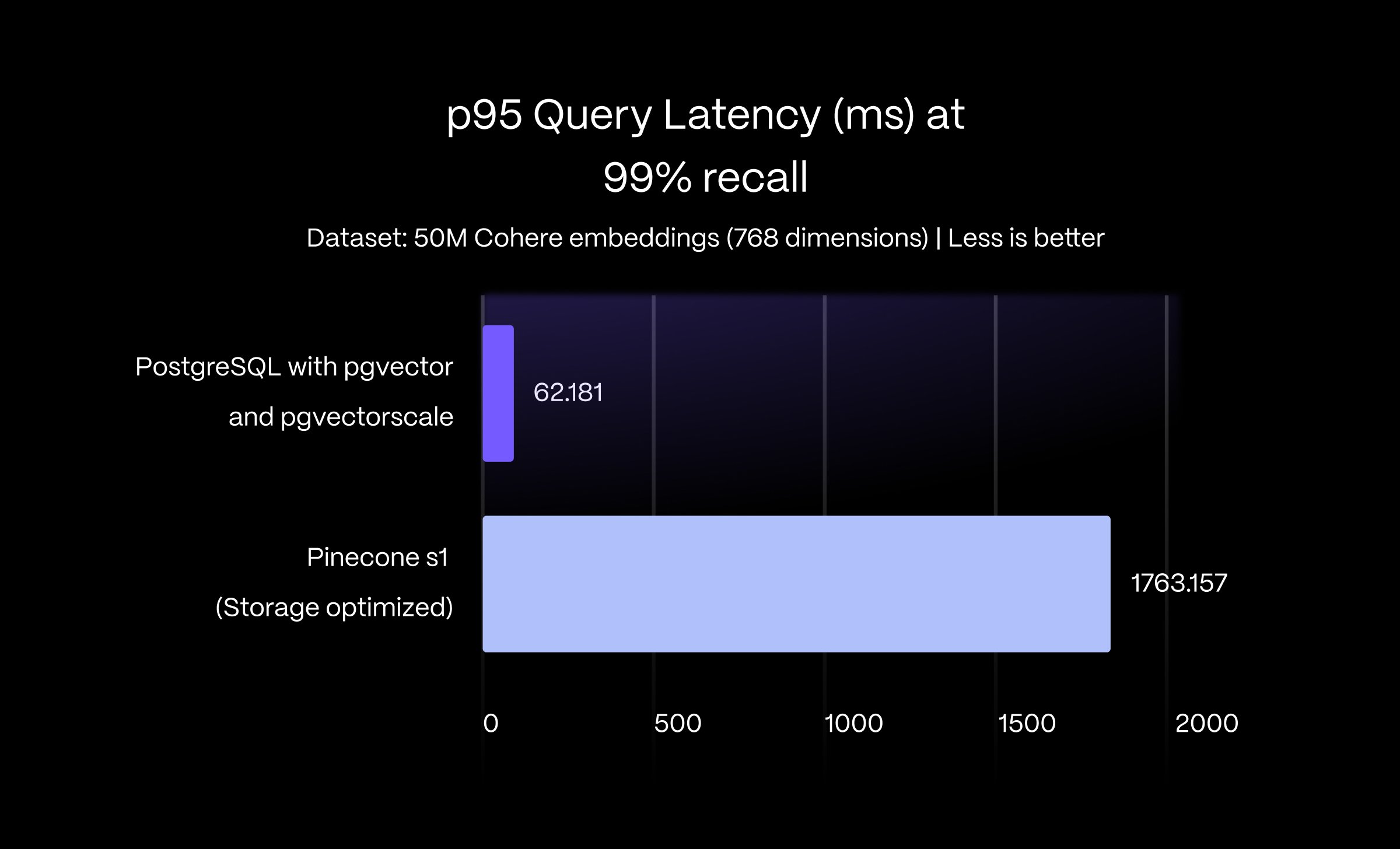
We also got the THE 150X PGVECTOR SPEEDUP: A YEAR-IN-REVIEW article. This is picking speed, folks.
Colocated data
In a setup with a relational database and a vector database, you usually have to double store metadata to make it queryable within both systems. With postgres, you can just add a new column to store your embeddings alongside your existing data (or metadata, call it whatever).
This has many advantages, a few being:
- Simplifies querying by using SQL for both relational data and embeddings
- Guarantees data consistency by eliminating the need for synchronization between separate databases
- Improves performance by reducing network round trips and fetching data in a single query
Retrieval in RAG (& hybrid search)
This has become one of the most common use cases for vector databases. It’s great and usually provides a much better user experience when implemented correctly. Postgres with its extensions and capabilities let you build a robust search engine that combines semantic, full-text, and fuzzy search techniques.
For a comprehensive walkthrough on implementing this retrieval system I’ve written Postgres as a search engine. It provides step-by-step instructions and explains the rationale behind each component of the system.
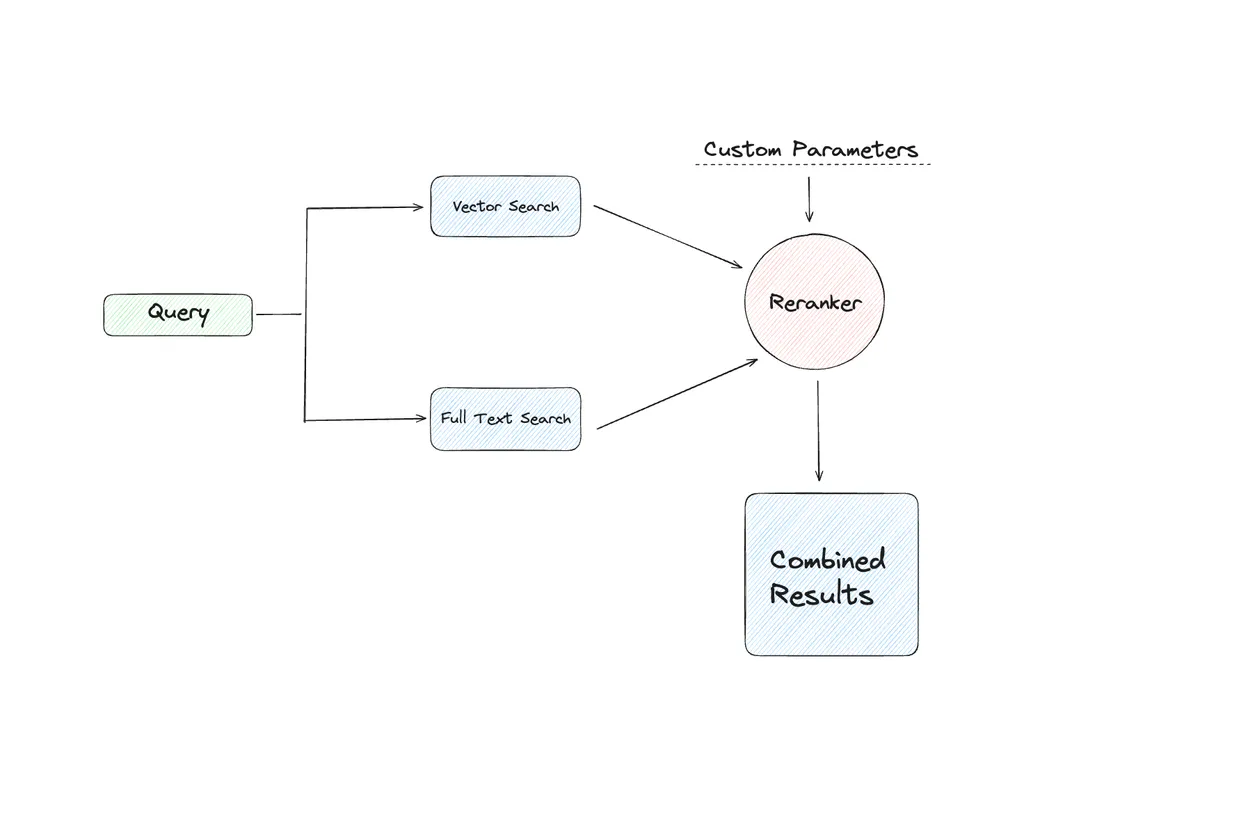
Knowledge graphs
Knowledge graphs are a powerful way to represent and connect entities and their relationships. They provide a flexible and intuitive structure for modeling complex domains, making it easier to derive insights and answer questions that span multiple entities.
Usually, you reach for a Graph Database like Neo4j, but you might not have to. Viktor at Sana Labs has written an excellent article on how to model and query graphs in Postgres. Read it here: You don’t need a graph database: Modeling graphs and trees in PostgreSQL
How do I use it?
Installation
Hosted
A great benefit of building this technology on top of giants is that great companies will continue to push the envelope of what is possible with Postgres. Getting started with pgvector is extremely easy if you’re using a hosted provider like Neon or Supabase. One single query
CREATE EXTENSION vector;Local
- download binary
- install extension
Here’s simple guide for getting it running with docker: Docker with postgres and pgvector extension
Using
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(1536) -- based on OpenAI `text-embedding-3-small`
);SELECT id, 1 - (vector <=> '[0.1, 0.2, 0.3]'::vector) AS cosine_similarity
FROM vectors
ORDER BY cosine_similarity DESC;You want an index on the embeddings. There are great articles on the pros & cons of using IVF-Flat vs HNSW
- AN EARLY LOOK AT HNSW PERFORMANCE WITH PGVECTOR
- Vector Indexes in Postgres using pgvector: IVFFlat vs HNSW
Is it a silver bullet?
Yes. Sort of. It’s a complex topic, and these are only simple answers.
What I found being the biggest catch has been around hybdrid search. The tsvector requires a lot of tuning to get right which can be troublesome. The lack of BM25 support (afaik) is also a bummer. There are also other interesting projects solving problems in this adjacent area. One of them is ParadeDB
You might not get all the bells and whistles of the purpose built vector databases, but I haven’t found myself using those anyway. I’ve seen a good implementation of Vespa from the folks at danswer where they get hybdrid search (bm25 + semantic) with tuning some configuration. Looks neat!
But, does it scale? If you’re not solving imaginary scaling issues (at scale) you’ll probably come a long way with just this. Like mentioned, if you’re doing hybrid search you might want to start looking at alterantive solutions and benchmark them.

Bright future
All in all, I’m very bullish on the future of using relational databases for vector storage. I imagine we’ll get even more interesting extensions in the future with good abstractions like this
insert into items (embedding) values (embed($1, 1536))select item, related(items.description) from items where similarity(items.name, $1) > 0.9Exciting times ahead!